排序器¶
這頁能幫你做什麼¶
排序器 (Ranker) 用來把一批文件依「跟查詢有多相關」重新排序。檢索器 (Retriever) 從知識庫 (Knowledge Base) 撈回一堆候選文件後,前幾名不一定最貼題;接上排序器,就能再做一次精排,把最相關的內容往前推,提升回答品質。簡單說:檢索器負責「廣撒網撈回來」,排序器負責「精排挑最準」。建立好排序器後,就能在排序器 (Ranker) 任務或檢索 (Retrieval) 任務的「排序器」設定裡指定它。
開始前¶
前置需求
- Embedding 類型會用到嵌入模型 (Embedding Model);可在表單指定,未指定則使用系統預設嵌入模型。
- Cohere、Amazon 類型透過 Amazon Bedrock 提供,需所在 AWS 區域支援對應模型。
- Jaccard Similarity 類型不需要任何額外資源。
操作步驟¶
-
從左側資源選單進入「排序器」清單頁,點右上角沒有文字的「+」圖示按鈕開啟建立表單。
-
在「名稱」欄輸入名稱。
- 在「類型」選擇排序方式(Embedding、Jaccard Similarity、Cohere 或 Amazon)。不同類型會出現不同欄位,選好後的畫面差異見下方完整欄位說明。上方圖即為選「Embedding」後的樣子。
- 依所選類型填寫專屬欄位(Embedding 的「嵌入模型」,或 Cohere/Amazon 的「模型」「地區」)。
- 按右上角的「儲存」按鈕完成建立(見步驟 1 圖右上角)。
完整欄位說明¶
主表單先填所有類型共通的「名稱」與「類型」,選好類型後再填該類型專屬的欄位。
共同欄位(不分類型)¶
| 欄位 | 必填 | 預設 | 說明 |
|---|---|---|---|
| 名稱 | 是 | 無 | 排序器的識別名稱。最多 64 個字,不可用 default 開頭。 |
| 類型 | 是 | 無(需選擇) | 排序方式,四選一:Embedding、Jaccard Similarity、Cohere 或 Amazon。四者的適用情境與專屬欄位見下方四節。建立後無法修改。 |
類型在建立後鎖定
編輯既有排序器時「類型」為唯讀。需要不同類型請另建一個排序器。
不確定選哪個類型?
一句話判斷:
- 想用「語意相近」來排序、且已經有嵌入模型 → 選 Embedding,把文件與查詢都轉成向量比相似度。
- 只是想快速、不接任何外部模型 → 選 Jaccard Similarity,純比對詞語重疊度,最輕量。
- 內容跨語言、企業資料較複雜、要最準的語意排序 → 選 Cohere(透過 Amazon Bedrock)。
- 想用 Amazon 原生排序模型、已在用 AWS 生態 → 選 Amazon(透過 Amazon Bedrock)。
其中 Cohere 與 Amazon 走 Amazon Bedrock,需所在 AWS 區域支援;Embedding 需要嵌入模型;Jaccard Similarity 完全不需外部資源。
Embedding¶
把文件與查詢都轉成向量,依向量相似度排序,能處理「語意相近但用字不同」的內容。
適合:
- 想依語意相似性排序,而非字面重疊。
- 已經建好嵌入模型,或想沿用系統預設嵌入模型。
選「Embedding」後的表單,會多出一個「嵌入模型」欄位:
Embedding 類型的專屬欄位:
| 欄位 | 必填 | 預設 | 說明 |
|---|---|---|---|
| 嵌入模型 | 否 | 系統預設嵌入模型 | 指定用來產生向量的嵌入模型。未指定時使用系統預設模型。右側的編輯()鈕可挑選;可清除。 |
Jaccard Similarity¶
純比對兩段文字的詞語重疊度(Jaccard 係數)來排序,不需要任何外部模型,最輕量、最快。
適合:
- 想要最簡單、最省成本的排序,不接任何外部模型或雲端服務。
- 文件與查詢用詞固定、字面重疊就足以判斷相關性。
選「Jaccard Similarity」後,表單沒有任何額外欄位——填好「名稱」與「類型」即可建立:
此類型除了共同欄位外沒有專屬欄位。
Cohere¶
透過 Amazon Bedrock 使用 Cohere 的排序模型,推理與多語言能力強,能準確排序複雜的企業資料,適用於精確語意理解與跨語言檢索。
適合:
- 內容跨多種語言,或專業領域資料較複雜。
- 想要最準的語意排序,且環境的 AWS 區域支援 Cohere 模型。
選「Cohere」後,表單會多出「模型」與「地區」兩個欄位(「模型」已自動預選唯一選項):
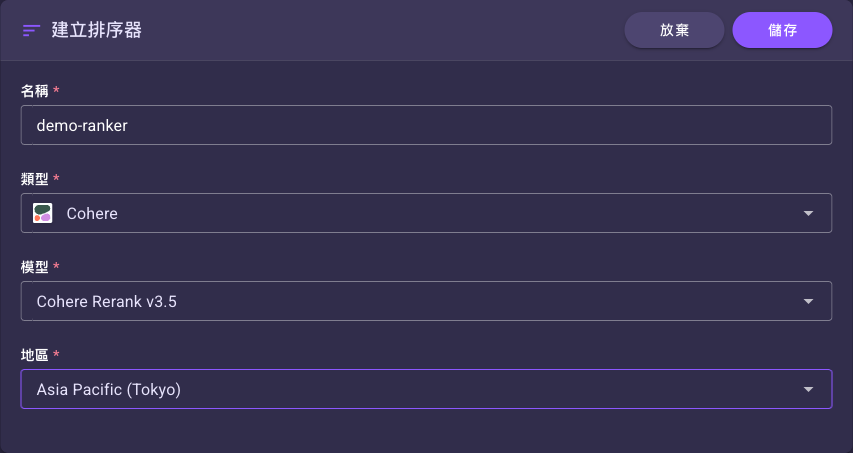
Cohere 類型的專屬欄位:
| 欄位 | 必填 | 預設 | 說明 |
|---|---|---|---|
| 模型 | 是 | Cohere Rerank v3.5 | Cohere 排序模型。選 Cohere 類型後已自動預選唯一選項 Cohere Rerank v3.5。 |
| 地區 | 是 | 無(需選擇) | 模型執行的 AWS 區域。選項見下方 tip。 |
Amazon¶
透過 Amazon Bedrock 使用 Amazon 原生的排序模型,能理解文字語義並依相關性排序。
適合:
- 已在使用 AWS 生態,想用 Amazon 原生排序模型。
- 想要語意排序,且環境的 AWS 區域支援 Amazon 模型。
選「Amazon」後,表單同樣會多出「模型」與「地區」兩個欄位(「模型」已自動預選):
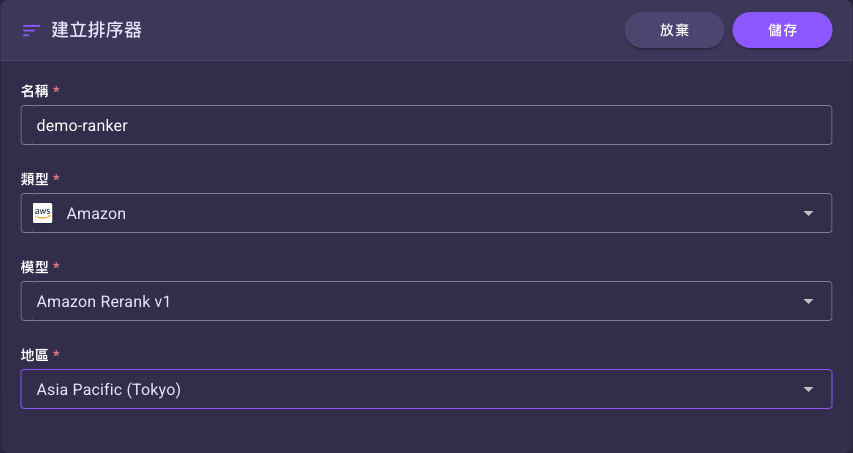
Amazon 類型的專屬欄位:
| 欄位 | 必填 | 預設 | 說明 |
|---|---|---|---|
| 模型 | 是 | Amazon Rerank v1 | Amazon 排序模型。選 Amazon 類型後已自動預選 Amazon Rerank v1。 |
| 地區 | 是 | 無(需選擇) | 模型執行的 AWS 區域。選項見下方 tip。 |
「地區」怎麼選
Cohere 與 Amazon 的「地區」是模型在 Amazon Bedrock 上執行的 AWS 區域,兩者選項相同:
| 選項 | 區域 |
|---|---|
| Asia Pacific (Tokyo) | 東京(ap-northeast-1) |
| Canada (Central) | 加拿大中部(ca-central-1) |
| US West (Oregon) | 美西奧勒岡(us-west-2) |
選離你的使用者較近、且該區域已開通對應模型的區域即可;不確定時先選預設清單中的任一個試跑,遇到模型未開通的錯誤再換區域。
排序器詳細頁¶
建立完成後點進某個排序器,詳細頁上方有三個頁籤;下圖為「一般」頁籤的「詳細資料」卡片,可看到 ID、名稱、類型、模型、地區與目前狀態:
| 頁籤 | 內容 |
|---|---|
| 一般 | 排序器的基本資料:ID、名稱、類型、模型、地區(依類型而定)與狀態。卡片右上角的複製()鈕可複製這個排序器,旁邊的收合鈕可收合卡片。 |
| 依賴資源 | 這個排序器用到的其他資源(例如 Embedding 類型會用到的嵌入模型)。 |
| 被依賴資源 | 反過來,有哪些資源用到這個排序器。 |
排序器沒有「驗證」功能
排序器詳細頁不提供「驗證憑證/測試連線」按鈕——它不直接連外部系統。要確認它有沒有用,請看下方「使用效果」,用實際排序結果驗證。
使用效果¶
排序器不能單獨執行,它的價值在於「把檢索回來的候選文件重新排好」。檢索器只負責「廣撒網」把可能相關的文件都撈回來,常常前幾名不一定最貼題;排序器接在後面做「精排」,依與查詢的相關性重新計分排序,把最相關的往前推,並可過濾掉相關性過低的雜訊文件。最後交給大型語言模型的內容因此更精準、也更省 Token。
建立好的排序器會在這些地方被選用:
- 排序器 (Ranker) 任務:拿一份既有文件清單(通常來自上游檢索器的輸出)重新排序,是排序器最直接的使用方式。
- 檢索 (Retrieval) 任務:在「排序器」設定指定它,讓同一個任務一次完成「檢索 + 排序」。
精排前後的差別
同一份候選文件清單,接排序器前是檢索器原本的順序(可能把字面命中但不夠貼題的文件排在前面);接排序器後會依與查詢的相關性重新排序,最相關的往前、雜訊往後或被門檻過濾掉。實際的查詢與門檻設定方式見排序器 (Ranker) 任務。
下一步¶
- 檢索器 (Retriever):先撈出候選文件,再交給排序器精排。
- 知識庫 (Knowledge Base):資料來源倉庫。
- 嵌入模型 (Embedding Model):Embedding 類型所需的模型。
- 排序器 (Ranker) 任務:在工作流程中實際使用排序器。
- 檢索 (Retrieval) 任務:一次完成檢索 + 排序。