載入器¶
這頁能幫你做什麼¶
載入器 (Loader) 是把外部資料「灌進知識庫」的橋樑。你指定資料從哪來(Amazon S3、OpenSearch、MySQL、API Endpoint、儲存庫 (Storage))、要寫進哪個知識庫、用哪些檢索器,平台就會自動讀取、切塊、轉成向量並寫入。還能設定排程定時自動同步,讓知識庫的內容跟著來源更新。簡單說:知識庫是「空倉庫」,載入器負責「進貨」。
開始前¶
前置需求
- 需先建立要寫入的知識庫 (Knowledge Base)(Vector 類型),且該知識庫尚未被其他載入器佔用。
- 需先建立至少一個檢索器 (Retriever)(Embedding/Keyword/Hybrid Search 類型)。
- 來源若是外部系統(S3、OpenSearch、MySQL、API),需先建立對應的連結器 (Connector);來源若是平台內的儲存庫 (Storage),需先有對應儲存庫。
- 自動載入器與部分非結構化檔案會用到大型語言模型 (LLM) 與分割器 (Chunker)。
下拉是空的怎麼辦
建立載入器時,「知識庫」與「檢索器」是兩個下拉選單。如果你是新帳號、還沒建過這些資源,這兩個下拉很可能是空的,會卡住無法繼續。請先依下列順序把前置資源建好,再回到本頁建立載入器:
- 先建一個 Vector 類型的知識庫 (Knowledge Base)(且尚未被其他載入器佔用)。
- 再建至少一個檢索器 (Retriever)(Embedding/Keyword/Hybrid Search 類型)。
- 若來源是外部系統,再建對應的連結器 (Connector);若來源是平台檔案,建一個儲存庫 (Storage)。
- 完成後回到「載入器」清單頁重新建立,下拉就會出現可選項目。
操作步驟¶
-
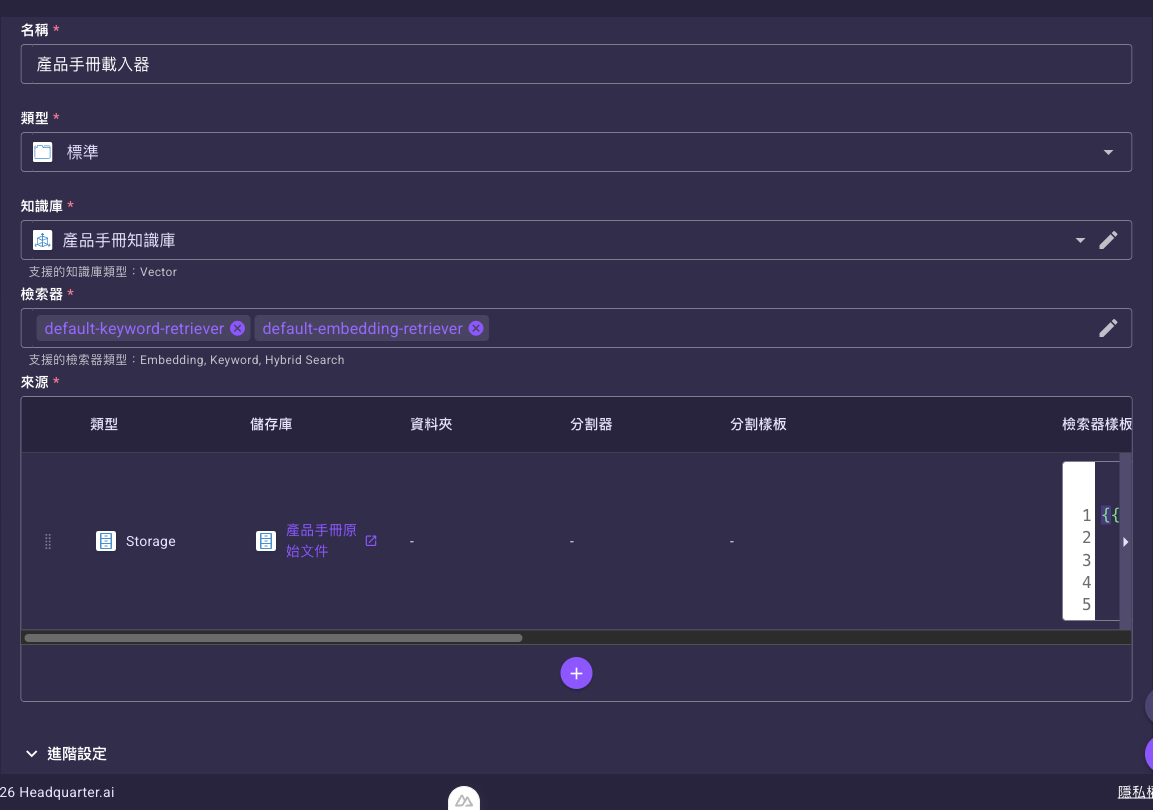
從左側資源選單進入「載入器」清單頁,點建立入口(空清單時是有文字的建立按鈕;清單已有項目時是右上角無文字的「+」圖示)開啟建立表單。
-
在「名稱」欄輸入名稱、在「類型」選「標準」或「自動」,並選好要寫入的「知識庫」與要綁定的「檢索器」(可多選)。上方建立表單圖即為「標準」類型填好這幾欄的樣子。
-
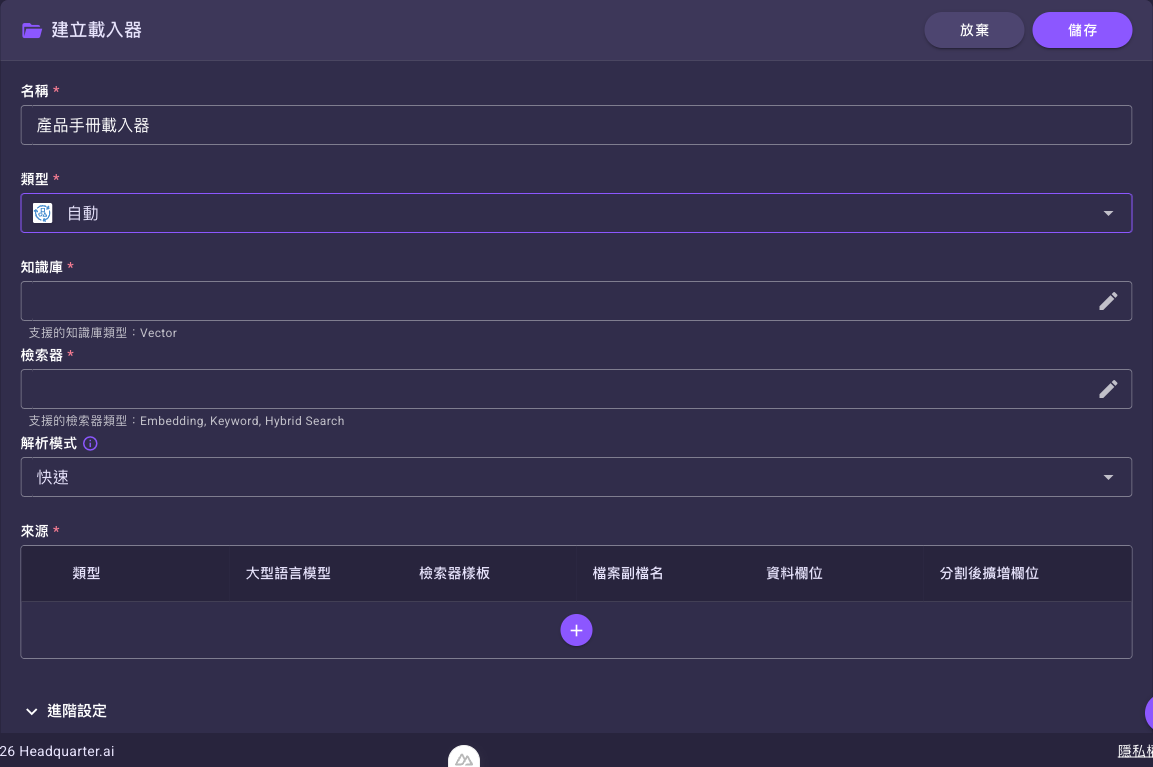
若「類型」選「自動」,下方會多出一個「解析模式」欄位,請選一個解析模式(標準/快速/專業,差異見解析模式怎麼選)。
-
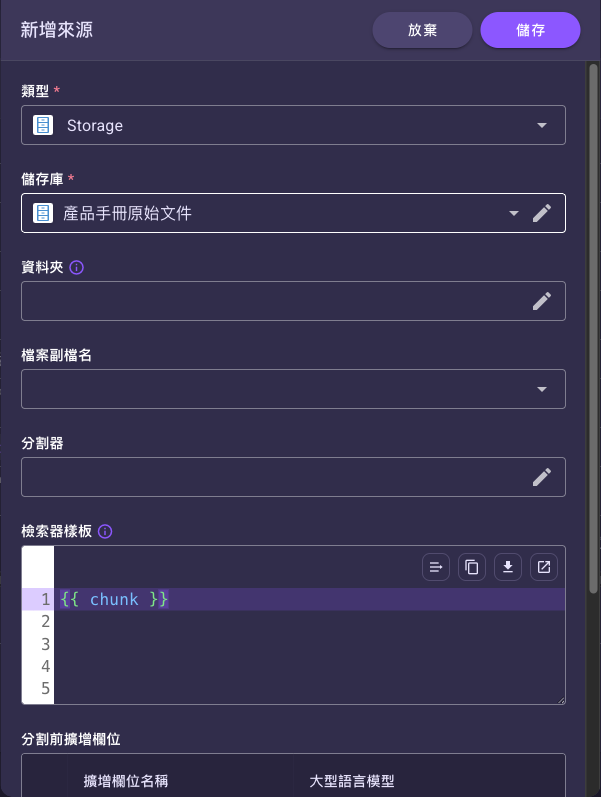
在「來源」表格按右側的「+」新增,於彈出視窗選好資料來源並設定切塊/樣板等細節後存檔。
-
視需要展開「進階設定」,在「同步任務」填入 AWS cron 表達式設定自動同步排程(留空則只靠手動觸發)。

-
按表單右上角的「儲存」按鈕完成建立(見步驟 1 圖右上角),之後可在詳細頁手動觸發同步或等排程執行。
完整欄位說明¶
主表單欄位分成兩部分:先填所有類型共通的「名稱」與「類型」,選好類型後,再填該類型專屬的欄位。
共同欄位(不分類型)¶
| 欄位 | 必填 | 預設 | 說明 |
|---|---|---|---|
| 名稱 | 是 | 無 | 載入器的識別名稱。最多 64 個字,不可用 default 開頭。 |
| 類型 | 是 | 無(需選擇) | 載入方式,二選一:標準或自動。兩者的適用情境與專屬欄位見下方兩節。建立後無法修改。 |
類型在建立後鎖定
編輯既有載入器時「類型」為唯讀。需要不同類型請另建一個載入器。
標準類型¶
把資料轉成向量或關鍵字後存入知識庫,且可自己控制切塊(指定分割器與分割樣板)。支援來源最廣:S3、OpenSearch、MySQL、API Endpoint、儲存庫。
適合:
- 來源是資料庫、API、CSV/JSON 等結構化資料(可對應資料欄位)。
- 想自己決定每塊多大、用什麼分隔符。
選「標準」後,主表單長這樣(已填好名稱、類型、知識庫與檢索器):
標準類型的專屬欄位:
| 欄位 | 必填 | 預設 | 說明 |
|---|---|---|---|
| 知識庫 | 是 | 無 | 資料要寫入的知識庫。僅能選 Vector 類型,且只列出未被其他載入器佔用、或正由此載入器使用的知識庫。 |
| 檢索器 | 是 | 無 | 與此載入器綁定的檢索器,可多選。僅支援 Embedding、Keyword、Hybrid Search 類型。 |
| 來源 | 是 | 無 | 表格,至少一筆。每筆代表一個資料來源,點新增後在彈出視窗設定(見來源設定)。 |
| 同步任務 | 否 | 無 | 位於「進階設定」摺疊區塊。以 AWS cron 表達式設定自動同步排程;留空表示僅手動同步。 |
自動類型¶
不用自己設切塊,直接把原始檔案交給大型語言模型自動解析與切分,連圖片內容都讀得出來。來源僅支援 S3 與儲存庫。
適合:
- 來源是一堆 PDF、Word、簡報、圖片等原始檔案,不想自己設切塊。
- 文件版面複雜(含表格、多欄、掃描檔),固定規則切不好。
選「自動」後,主表單會把「分割器/分割樣板」換成一個「解析模式」欄位(解析模式怎麼選見下一節):
自動類型的專屬欄位:
| 欄位 | 必填 | 預設 | 說明 |
|---|---|---|---|
| 知識庫 | 是 | 無 | 同標準類型。 |
| 檢索器 | 是 | 無 | 同標準類型,可多選。 |
| 解析模式 | 是 | 無(需選擇) | 大型語言模型解析原始檔案的方式,三種選法見下節。 |
| 來源 | 是 | 無 | 表格,至少一筆。設定方式見來源設定(自動類型來源僅支援 S3 與儲存庫)。 |
| 同步任務 | 否 | 無 | 位於「進階設定」摺疊區塊,同上。 |
解析模式怎麼選¶
自動類型要再選一個解析模式。三者畫面相同(都是上圖那個「解析模式」下拉),差別在解析方式與速度:
| 解析模式 | 適合 | 怎麼解析 |
|---|---|---|
| 標準 | 一般文件,要兼顧解析品質與速度 | 用大型語言模型做較完整的解析與切分 |
| 快速 | 檔案數量多、想優先衝處理速度 | 用較快的固定切分方式 |
| 專業 | 版面複雜(表格、多欄、掃描檔),固定規則切不好 | 把原始檔以附件交給大型語言模型,解析最完整 |
來源設定(彈出視窗)¶
在「來源」表格按新增時會開啟一個設定視窗。先選「類型」,再依來源類型填寫對應的連結器/儲存庫欄位,最後設定切塊與樣板。下圖以最單純的 Storage 來源為例(選好儲存庫,其餘欄位皆選填):
若改選外部來源(如 Amazon S3),則會改為要求「連結器」與該來源專屬欄位(S3 儲存貯體、S3 字首…):
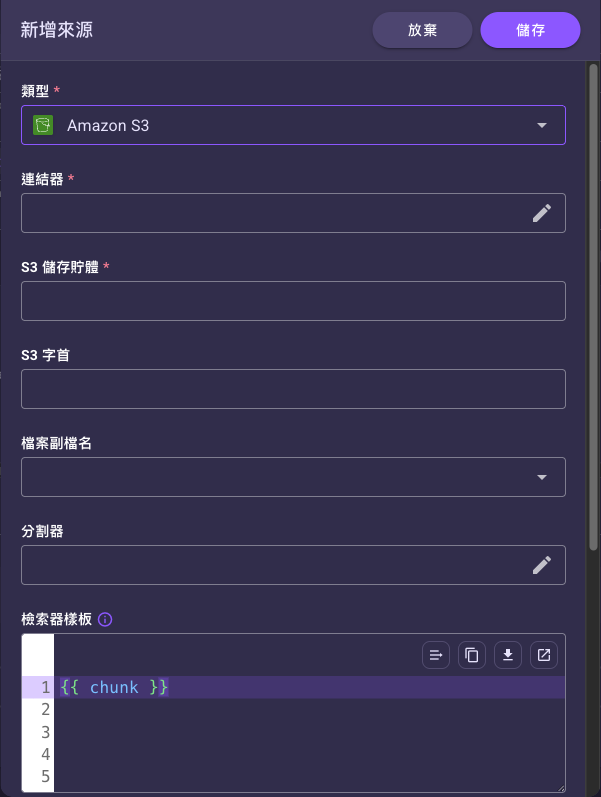
| 欄位 | 必填 | 預設 | 說明 |
|---|---|---|---|
| 類型 | 是 | 無 | 資料來源類型。標準類型可選 Amazon S3、OpenSearch、MySQL、API Endpoint、Storage;自動類型只可選 Amazon S3、Storage。選定後出現對應的連結器設定欄位。 |
| 連結器/儲存庫相關欄位 | 視來源 | — | 依來源類型不同:S3 需選連結器並填 S3 儲存貯體、S3 字首、檔案副檔名;OpenSearch 需選連結器並填 OpenSearch 索引名稱、最後修改時間欄位、HTTP 標頭;MySQL 需選連結器並填資料庫名稱、資料表名稱、最後修改時間欄位;API Endpoint 需選連結器;Storage 需選儲存庫、資料夾與檔案副檔名。各連結器欄位細節見連結器 (Connector)。 |
| 分割器 | 否 | 無 | 標準類型來源可選的分割器,控制此來源文件如何切塊。可清除。詳見分割器 (Chunker)。 |
| 分割樣板 | 視情況 | {{ content }} | 切塊時的內容格式(Jinja 樣板,用法見下方說明)。僅在已選分割器時出現、且必填;當來源是 S3/Storage 且全部為非結構化檔案時鎖定為預設值(唯讀)。 |
| 檢索器樣板 | 否 | {{ chunk }} | 每個切塊最後被檢索/回傳的文字格式(Jinja 樣板,用法見下方說明)。綁定的檢索器全部為 Keyword 類型時不出現。 |
| 資料欄位 | 否 | 無 | 設定 OpenSearch 欄位對應(來源欄位至目的欄位)。僅在結構化來源(CSV/TSV/JSON/JSONL,或 OpenSearch/MySQL/API 來源)可用;其他情況為停用狀態。 |
| 分割前擴增欄位 | 否 | 無 | 表格(僅標準類型)。在切塊「之前」用大型語言模型替每筆資料產生新欄位,詳見「擴增欄位設定」。 |
| 分割後擴增欄位 | 否 | 無 | 表格。在切塊「之後」替每個區塊用大型語言模型產生新欄位。標準與自動類型皆有此欄位。 |
「分割樣板」和「檢索器樣板」差在切塊的前與後
兩個都是 Jinja 樣板,但作用在切塊的不同階段,別搞混:
- 分割樣板(切塊「前」,預設
{{ content }}):決定「要被切的那段文字長什麼樣」。 - 檢索器樣板(切塊「後」,預設
{{ chunk }}):決定「切好的每一塊,最後要以什麼形式被檢索與回傳」(檢索時這段文字會放在結果的retriever_chunk欄位)。
一句話:分割樣板管「切什麼」,檢索器樣板管「切完每塊長怎樣、回傳什麼」。
以一筆有 title、body、category 三個欄位的 FAQ 資料為例,幾種常見寫法:
- 分割樣板
{{ title }} - {{ body }}:把標題和內文一起交給分割器切,讓每塊都保有問題脈絡(預設{{ content }}只切單一內容欄位)。 - 檢索器樣板
{{ title }} - {{ chunk }}:每段檢索結果開頭都帶上問題標題。 - 檢索器樣板
[{{ category }}] {{ chunk }}:每段結果加上分類前綴,方便後續大型語言模型判讀這段來自哪類文件。
自動來源的差異
自動類型的來源設定不含「分割器/分割樣板」,但會多一個「大型語言模型」選擇欄位用來解析檔案;當可能包含非結構化檔案時為必填。其餘(檢索器樣板、資料欄位、分割後擴增欄位)與標準類型相同。
OpenSearch/MySQL/API Endpoint 來源視部署而定
來源「類型」下拉是否出現 OpenSearch、MySQL、API Endpoint,會依平台部署設定而定;部分部署只開放 Amazon S3 與 Storage 兩種來源。若你的下拉看不到這三種,代表此環境未開放,請改用 S3 或 Storage 作為來源。
各來源支援的檔案副檔名
當來源是 Amazon S3 或 Storage 時,「檔案副檔名」欄位可挑選要納入的副檔名(留空表示不限)。兩種載入器類型支援的格式不同:
- 標準:
.csv、.tsv、.json、.jsonl、.gz、.html、.md、.txt、.pdf、.doc/.docx、.ppt/.pptx、.xls/.xlsx。 - 自動:
.csv、.tsv、.json、.jsonl、.md、.txt、.pdf、.docx、.ppt/.pptx、.xls/.xlsx,並額外支援圖片(.jpg、.jpeg、.png、.gif、.webp),可交由大型語言模型解析圖片內容。
其中 .csv、.tsv、.json、.jsonl(標準類型另含 .gz)視為「結構化檔案」,選用這些(且沒混入其他格式)時「資料欄位」才會啟用;混入 .pdf、.docx 等非結構化格式時「資料欄位」會停用。
最小可動來源:先只接一個 Storage
這個彈出視窗欄位很多,但大多是選填。新手第一次只要設好「最少必填」就能跑:
- 「類型」選
Storage。 - 選一個你已建好的儲存庫 (Storage),並(視需要)填資料夾與檔案副檔名。
- 其餘欄位(分割器、分割樣板、檢索器樣板、資料欄位、擴增欄位)全部留空。
- 存檔回到主表單即可。
等熟悉後再依需求加分割器或擴增欄位等進階設定。
擴增欄位設定(彈出視窗)¶
在「分割前/後擴增欄位」表格按新增時開啟,用大型語言模型替資料產生額外欄位。
| 欄位 | 必填 | 預設 | 說明 |
|---|---|---|---|
| 擴增欄位名稱 | 是 | 無 | 新欄位的名稱,不可與既有欄位重複,且不可用 content、chunk、retriever_chunk。 |
| 大型語言模型 | 是 | 無 | 選擇用來產生內容的大型語言模型資源;旁邊的調整()鈕可微調該模型參數。 |
| 對話 | 是 | 無 | 選好模型後出現。提供給模型的提示訊息內容。 |
| 使用 JSON Schema | 否 | 關閉 | 開關。開啟後模型改用結構化輸出,需再定義 JSON Schema。 |
| JSON Schema | 視情況 | 預設結構 | 開啟上方開關後出現,定義結構化輸出的格式,必填。 |
| 備用大型語言模型 | 否 | 無 | 主模型失敗時依序嘗試的備用模型清單。 |
| 允許重試 | 否 | 關閉 | 開關。開啟後在無法生成回應時重新生成,每次重試溫度值加 0.1。 |
分割前/分割後擴增欄位的範例
擴增欄位就是「請大型語言模型替資料多算一個欄位」,算完可在分割樣板、檢索器樣板或檢索時引用。差別在算的時機與對象:
- 分割前(對整筆資料算一次,僅標準類型):
summary——「對話」填「用一句話摘要以下內容:{{ body }}」,產生整篇摘要,之後可在檢索器樣板用{{ summary }}。language——判斷整篇語言(如zh/en),供後續過濾或分流。doc_type——把整篇分類成「FAQ/教學/公告」之一。
- 分割後(對每個切塊各算一次):
keywords——「對話」填「列出這段文字的 3–5 個關鍵字:{{ chunk }}」,增強關鍵字檢索命中率。possible_question——產生「這段內容能回答的問題」,做檢索增強。chunk_summary——把每塊濃縮成一句話。
擴增欄位名稱不可用 content、chunk、retriever_chunk,也不可與既有欄位重複。
載入器詳細頁的頁籤¶
建立完成後點進某個載入器,詳細頁上方有四個頁籤;下圖為「一般」頁籤,可看到名稱、類型、綁定的知識庫與檢索器,以及下方的來源設定:
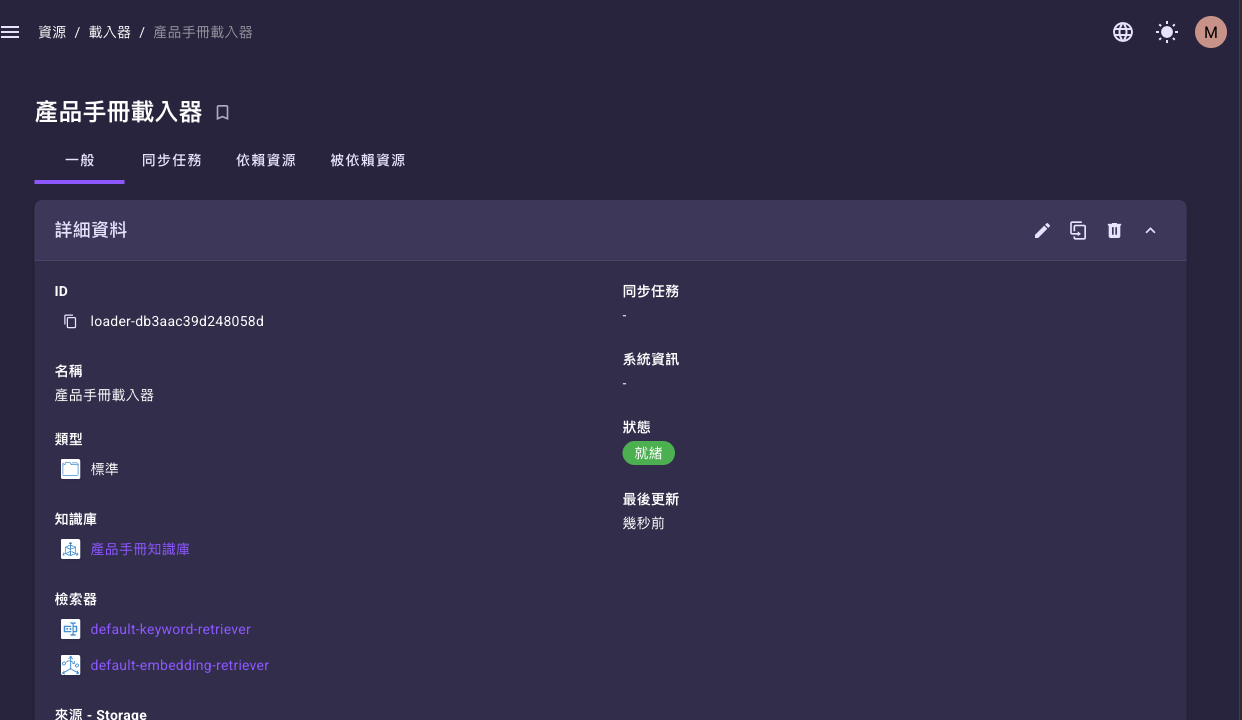
| 頁籤 | 內容 |
|---|---|
| 一般 | 載入器的基本資料:名稱、類型、綁定的知識庫與檢索器、各筆來源設定。可從這裡進入編輯、複製或刪除。 |
| 同步任務 | 這個載入器跑過與正在跑的同步任務 (Sync Job) 清單,也是手動觸發同步的入口。詳見下方「同步的執行方式」。 |
| 依賴資源 | 這個載入器用到的其他資源(知識庫、檢索器、連結器、分割器…)。 |
| 被依賴資源 | 反過來,有哪些資源用到這個載入器。 |
同步的執行方式¶
載入器建立後不會自動把資料灌進去,要「觸發同步」才會實際讀取來源、切塊、轉向量並寫入知識庫。同步任務 (Sync Job) 就是載入器實際執行的一次 ETL 工作:從來源擷取資料、用綁定的資源轉換(切塊、轉向量、擴增欄位),最後把結果(文字、向量等)寫入知識庫。觸發方式有兩種:
- 手動同步:到載入器詳細頁的「同步任務」頁籤按「開始新的同步任務」(右上角的 鈕;清單為空時則是中央的「開始」按鈕),在跳出的「開始同步任務」對話框設定選項後執行,立即跑一次。
- 排程同步:在建立/編輯時展開「進階設定」,點「同步任務」欄位右側的編輯()圖示開啟設定對話框,逐欄組出一條 AWS cron 排程,存檔後平台就依排程自動執行;「同步任務」留空則只靠手動觸發。
點該編輯()圖示,會開啟「新增同步任務」對話框,用六個欄位拼出排程時間:
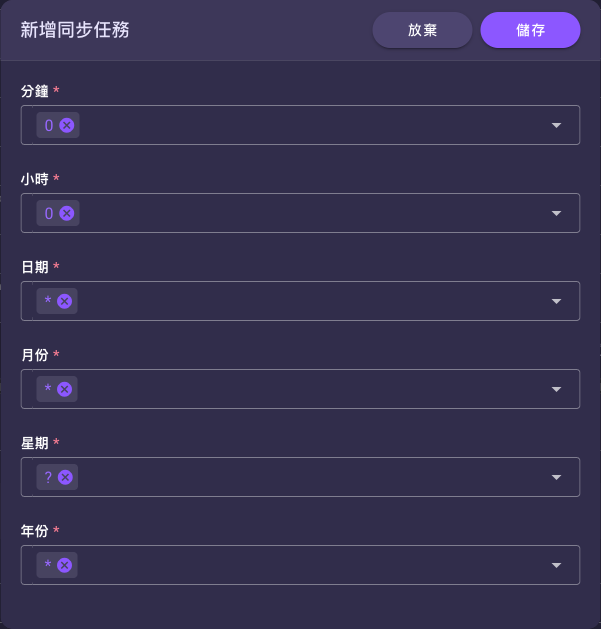
| 欄位 | 預設 | 設定什麼 |
|---|---|---|
| 分鐘 | 0 | 在第幾分鐘執行。 |
| 小時 | 0 | 在第幾小時執行。 |
| 日期 | * | 每月第幾天執行(* 為每天)。 |
| 月份 | * | 哪幾個月執行(* 為每月)。 |
| 星期 | ? | 星期幾執行。 |
| 年份 | * | 哪幾年執行(* 為每年)。 |
各欄可點下拉挑常見值。預設組合 0 0 * * ? * 代表「每天 00:00 自動同步一次」。
「日期」與「星期」不能同時指定
AWS cron 規定「日期」與「星期」其中一個必須留為 ?(預設星期為 ?);兩者都填具體值會衝突。
「同步任務」頁籤的清單與操作¶
每觸發一次同步就會在「同步任務」頁籤新增一筆紀錄。清單以表格呈現,欄位如下:
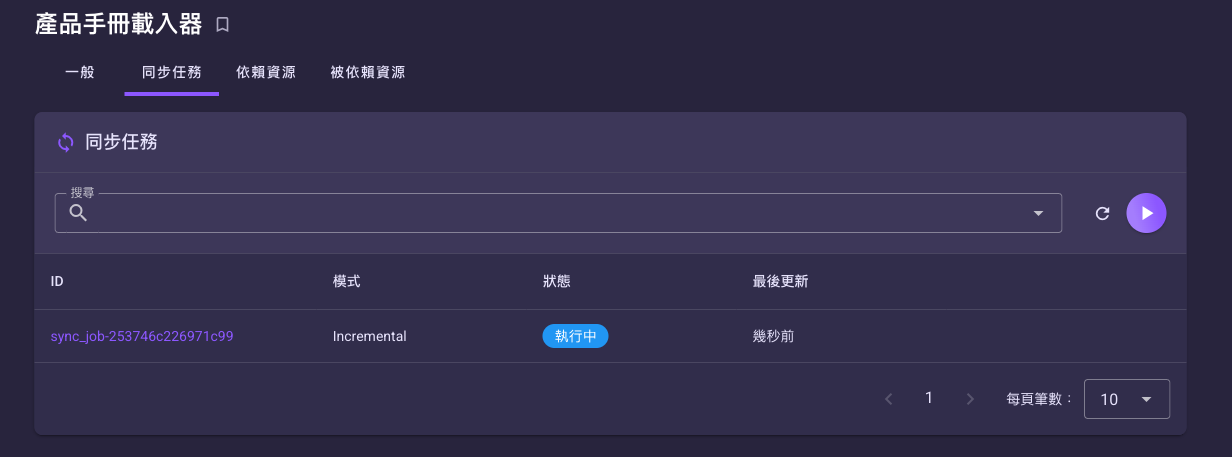
| 欄位 | 說明 |
|---|---|
| ID | 該次同步任務的識別碼。點進去可看這次同步的細節。 |
| 模式 | 這次同步的方式:Incremental(增量,只處理有變動的資料)或 Full(完整,整庫重建)。由觸發時「強制執行完整同步」開關決定,見下節。 |
| 狀態 | 執行狀態(如執行中、成功、失敗等)。 |
| 最後更新 | 這筆同步任務最後一次狀態更新的時間。 |
頁籤上的可用操作:
| 操作 | 位置 | 說明 |
|---|---|---|
| 開始新的同步任務 | 右上角 鈕 | 開啟「開始同步任務」對話框,手動觸發一次同步。 |
| 重新整理 | 右上角 鈕 | 重新載入清單,更新各筆任務的最新狀態。 |
| 停止 | 每一列的選單()內 | 中止該筆同步任務。僅在任務「執行中」時可點,其餘狀態為停用。 |
點任一筆同步任務的 ID 可進入該次同步的細節頁,看到這次跑了多少資料、花多久、成功或失敗:
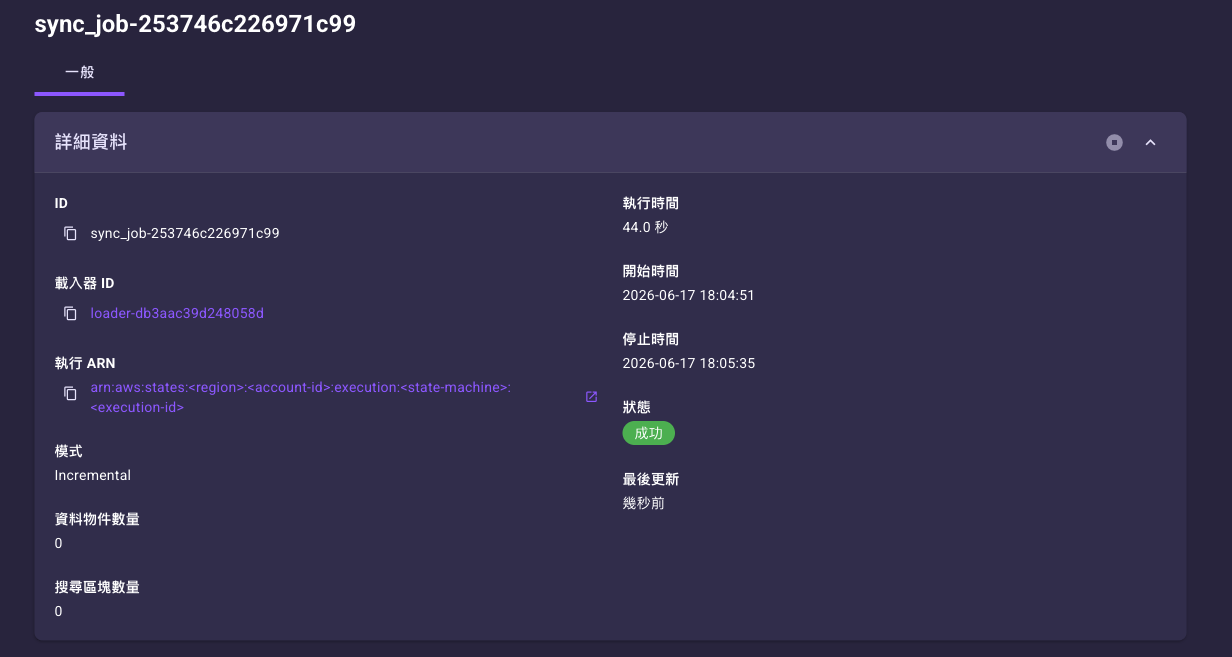
細節頁欄位:
| 欄位 | 說明 |
|---|---|
| ID | 該次同步任務的識別碼。 |
| 載入器 ID | 觸發這次同步的載入器,可點擊回到載入器詳細頁。 |
| 執行 ARN | 這次同步在底層執行的識別碼,用於技術除錯,一般使用者可忽略。旁邊的 開啟連結會導向底層 AWS 主控台,一般使用者多半會看到錯誤頁,可忽略,詳見通用介面元件。 |
| 模式 | Incremental(增量)或 Full(完整),見下節。 |
| 資料物件數量 | 這次同步實際處理的來源資料筆數。 |
| 搜尋區塊數量 | 切塊後寫入知識庫的區塊數。 |
| 執行時間 | 這次同步從開始到結束的總耗時。 |
| 開始時間/停止時間 | 這次同步的起訖時間。 |
| 狀態 | 這次同步的結果(成功、失敗、執行中等)。 |
| 最後更新 | 狀態最後一次更新的時間。 |
增量同步與完整同步¶
預設情況下同步是「增量」的——平台只處理新增或內容有變更的資料,沒變動的就跳過,避免每次都整庫重建,省時也省成本。是否變更的判斷依據是來源資料的「最後修改時間」加上內容比對;對 OpenSearch/MySQL 等來源,可在來源設定指定「最後修改時間欄位」(例如 updated_ts)作為判斷基準。
觸發同步時可調整兩個選項:
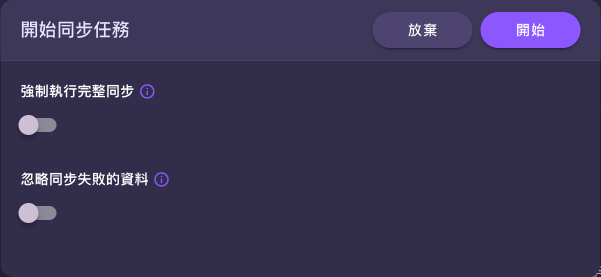
| 選項 | 預設 | 說明 |
|---|---|---|
| 強制執行完整同步 | 關閉 | 開啟後會清除知識庫既有資料並全部重新同步,忽略增量判斷。適合來源結構大幅調整、或懷疑資料不一致想整個重建時使用。 |
| 忽略同步失敗的資料 | 關閉 | 開啟後遇到個別資料同步失敗時略過該筆、繼續處理其餘資料,不讓單筆錯誤中斷整批。 |
API/HTTP 來源只新增或更新、不刪除
以 API Endpoint/HTTP 為來源的載入器,增量同步時即使來源少了某筆資料,也不會把知識庫裡對應的舊資料刪掉(僅新增或更新)。需要清掉舊資料時,改用「強制執行完整同步」。
使用效果¶
載入器的價值要「同步完、查得到」才看得出來。觸發同步後可從兩個地方確認資料真的進去了:
1. 同步任務細節頁出現實際筆數¶
到「同步任務」頁籤點進剛跑完的那一筆,「資料物件數量」與「搜尋區塊數量」會顯示這次實際讀入並切塊寫入的數量(畫面見上方單筆同步任務細節頁)。兩個數字大於 0,就代表來源內容已成功寫進知識庫。
2. 知識庫已經可以被問答¶
資料進了知識庫後,就能被檢索器 (Retriever)、檢索 (Retrieval) 任務或 Agent 的檢索工具查到。下圖是一個接了此知識庫的 Agent:使用者問「退換貨政策」,Agent 透過知識庫檢索工具找到剛灌進去的產品文件並據此回答——這代表載入器確實把來源內容變成了可被語意檢索的資料。
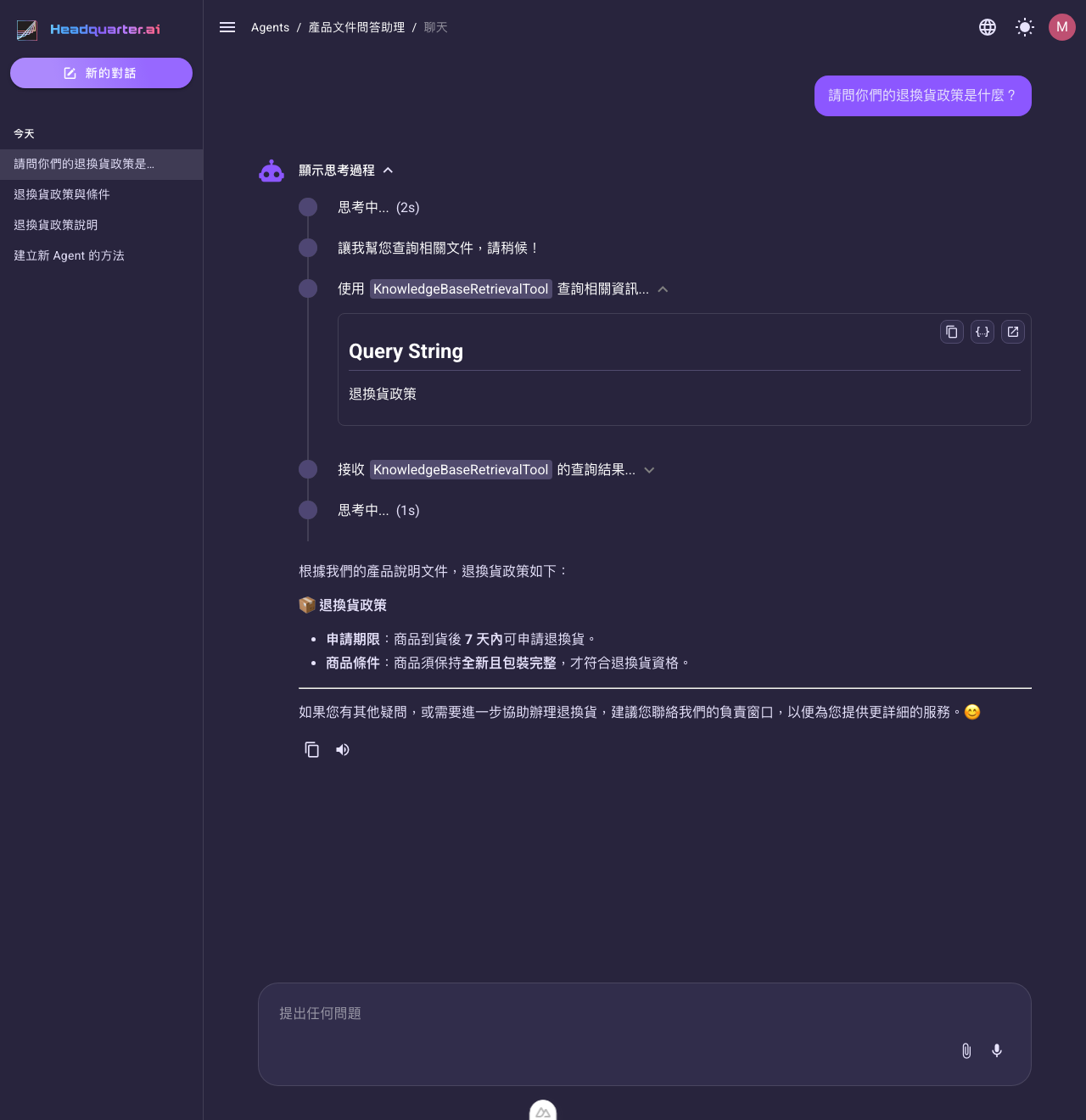
要把知識庫接給 Agent 或工作流程使用,見檢索 (Retrieval) 任務與檢索工具。
下一步¶
- 知識庫 (Knowledge Base):載入器寫入的目標倉庫。
- 檢索器 (Retriever):與載入器綁定、決定怎麼查。
- 分割器 (Chunker):來源切塊策略。
- 連結器 (Connector):S3/OpenSearch/MySQL/API 來源所需。
- 儲存庫 (Storage):以平台上傳檔案作為來源時使用。