讀取網址¶
這頁能幫你做什麼¶
Read URL 任務從指定的網址抓取網頁內容,並轉成乾淨的 Markdown 或保留原始 HTML,方便後續交給大型語言模型 (LLM) 處理、匯入知識庫或做資料分析。常見情境:
- 抓取文章、部落格或新聞內容,餵給 RAG 流程。
- 擷取文件頁面,匯入知識庫。
- 從網頁取得產品描述或規格。
- 把網頁內容轉成 Markdown,方便 LLM 閱讀。
開始前
一般網址不需任何前置資源。若目標網站需要驗證或特定連線設定,可選用一個 API 類型的連結器 (Connector) 來提供請求標頭(見下方欄位說明)。連結器建立方式見 Connector 資源頁。
操作步驟¶
-
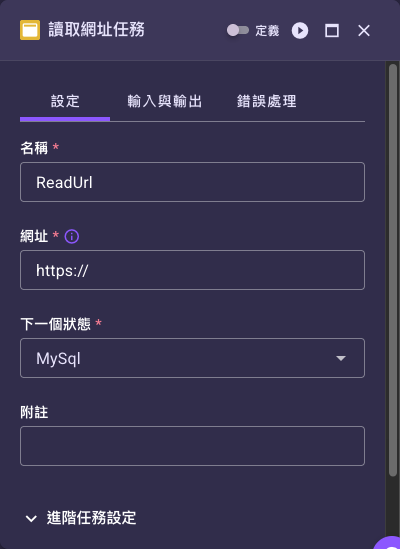
新增一個 Read URL 任務節點,點選它開啟右側設定表單。
-
在「名稱」填步驟名稱。
- 在「網址」填要讀取的網頁網址(必須是
http://或https://開頭的合法網址),也可用 JSONPath 從輸入帶入(路徑寫法見 JSONPath 語法)。 -
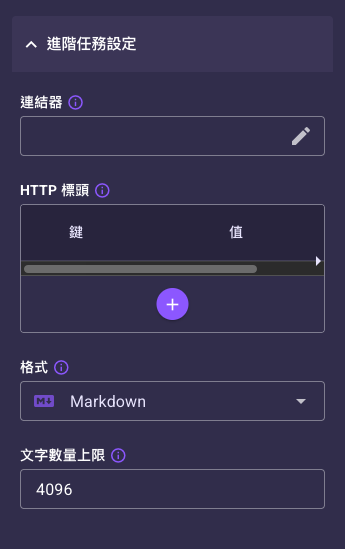
視需要展開「進階任務設定」設定連結器、HTTP 標頭、格式與文字數量上限。
-
設定「下一個狀態」,視需要填「附註」,再用測試按鈕()試跑。
完整欄位說明¶
下表只列 Read URL 任務特有的欄位。名稱、附註、下一個狀態、輸入與輸出、錯誤處理等共用分區,請見 Action 通用設定。
設定分頁(基本欄位)¶
| 欄位 | 必填 | 預設 | 說明 |
|---|---|---|---|
| 網址 | 是 | https:// | 要讀取的網頁網址,支援靜態頁面。必須是 http:// 或 https:// 開頭的合法網址。可用 JSONPath 從輸入帶入,例如 $.article_url。 |
進階任務設定(摺疊區塊)¶
展開設定分頁底部的「進階任務設定」可看到下列 Read URL 特有欄位:
| 欄位 | 必填 | 預設 | 說明 |
|---|---|---|---|
| 連結器 | 否 | 無 | 選用一個 API 類型的連結器來提供請求標頭,可安全存放敏感資訊(如驗證金鑰)。若直接在 HTTP 標頭填寫,值會以明文儲存且不受保護。可清除、也可從輸入動態帶入。建立方式見 Connector 資源頁。 |
| HTTP 標頭 | 否 | 空(無自訂標頭) | 要附加到請求的自訂 HTTP 標頭,例如 User-Agent、Authorization、Cookie。某些網站會擋預設爬取,可加自訂 User-Agent 降低被封鎖機率。需隱藏敏感資訊時建議改用連結器。可切換成 JSON 輸入。 |
| 格式 | 否 | Markdown | 從網頁讀出的內容格式。可選 Markdown(輕量標記語言,呈現結構化資訊,建議用於 LLM)或 HTML(原生網頁格式,保留完整排版與結構)。 |
| 文字數量上限 | 否 | 4096 | 讀取內容的最大字數,用來限制長度避免內容過長壓垮 LLM。最小 1024。清空代表不設上限、讀取完整內容。 |
Note
「文字數量上限」欄位可清空;清空時不套用字數限制。預設 4096、最小 1024 以後端實際設定為準。
實際範例與預期結果¶
設定內容:
- 網址:
$.article_url - 格式:Markdown
- 文字數量上限:
2000
工作流程輸入:
{
"article_url": "https://example.com/articles/ai-trends"
}
測試輸出(讀到的內容放在 read_url_output):
{
"errors": null,
"action_type": "read_url_action",
"read_url_output": "# 2025 年 AI 趨勢\n\n人工智慧持續快速發展,出現了幾個關鍵趨勢..."
}
Note
輸出以後端實際回傳為準:讀到的內容放在 read_url_output,action_type 固定為 read_url_action。選 Markdown 時內容為 Markdown 文字,選 HTML 時為 HTML。
下一步¶
- 用 Search Engine 任務 找出要抓取的網址,再串到這個任務。
- 用 程式碼 (Code) 任務 擷取內容中的特定區段。
- 把內容交給 LLM 任務 做摘要或分析。
- 回到 Action 通用設定 了解共用分區。