大型語言模型¶
大型語言模型任務讓你在工作流程裡呼叫一個大型語言模型 (LLM),根據你給的對話內容產生文字回應。它是問答、摘要、內容生成、改寫、對話式 AI 等場景的核心步驟。
這也是整個平台最常被用到的任務之一,而它的成效幾乎全看「提示詞 (Prompt) 怎麼寫」。本頁除了逐欄說明設定,也用一整節「怎麼寫提示詞」教你把系統提示詞、使用者訊息與樣板 (Template) 組起來,並附上可直接套用的範例。
這頁能幫你做什麼¶
- 用知識庫檢索到的內容回答使用者問題(RAG)。
- 從來源資料產生摘要、信件、報告或文件。
- 打造能理解上下文的對話介面。
- 以不同語氣、格式或語言改寫文字(例如同一份氣象資訊,對民眾與對署內用不同口吻)。
本頁只說明 LLM 任務特有的欄位。名稱、附註、下一個狀態、輸入與輸出、錯誤處理,以及進階任務設定與執行設定中的共用開關,都集中在 Action 通用設定。
開始前¶
需要先建立 LLM 資源
LLM 任務必須綁定一個已建立的 大型語言模型 (LLM) 資源(指定供應商、模型與金鑰)。如何建立請見 LLM 資源。
操作步驟¶
-
在工作流程編輯器中新增一個 大型語言模型 任務(新增 Action 的通用步驟見 Action 使用指南)。
-
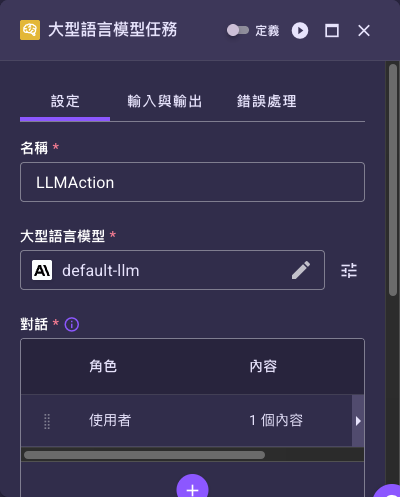
在「名稱」填入這個步驟的識別名稱。
-
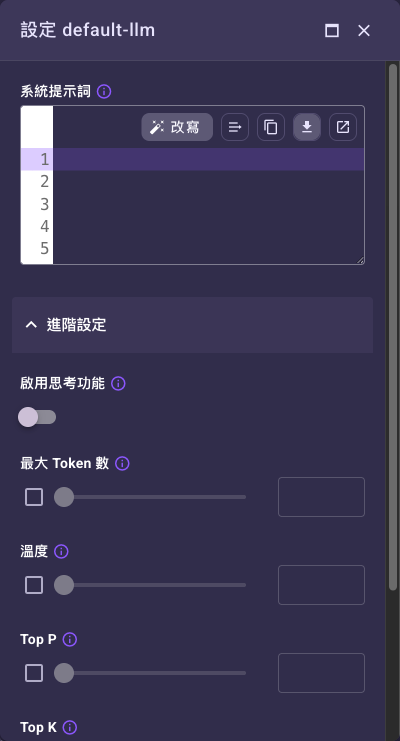
在「大型語言模型」欄位選擇要使用的 LLM 資源。選好後,可點欄位旁的調整()圖示開啟設定對話框,覆寫這次呼叫的系統提示詞與模型參數(系統提示詞、溫度、最大 Token 數等,欄位內容來自該 LLM 資源)。
-
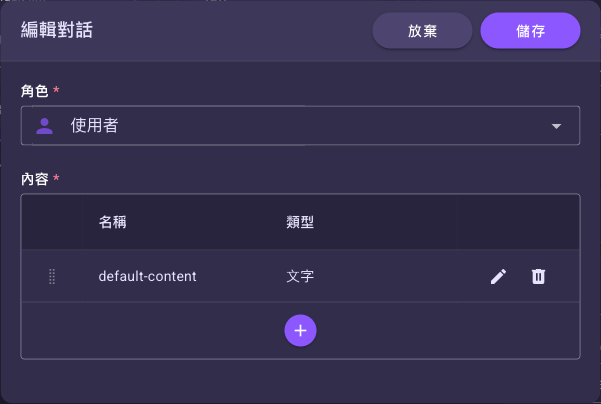
在「對話」表格逐列加入訊息。點某列的編輯()鈕會先開啟「編輯對話」對話框,在這裡設定該列的「角色」(使用者/系統助理)並管理底下的「內容」子表。
-
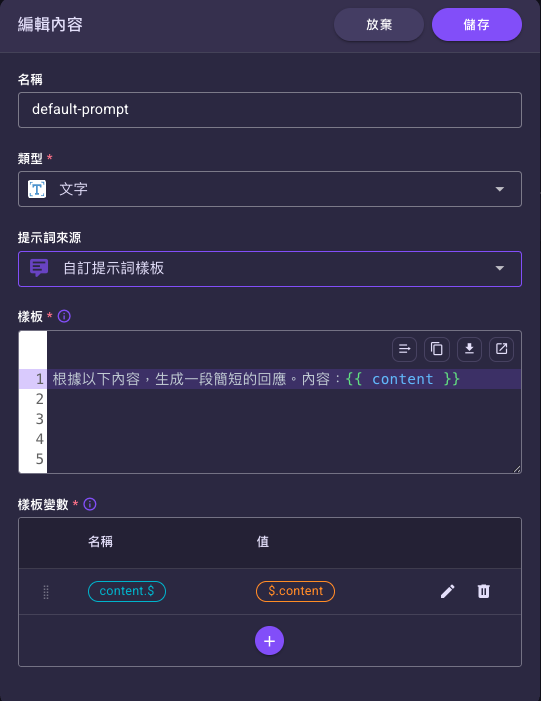
在「編輯對話」對話框的「內容」子表,點某列的編輯()鈕會再開出「編輯內容」對話框;在這裡選「提示詞來源」並把動態值(如病人主訴)帶進提示詞。
-
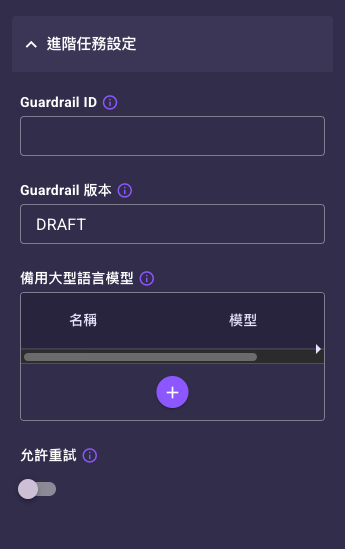
視需要展開「進階任務設定」設定 Guardrail、備用模型、允許重試等。
-
設定「下一個狀態」,必要時填「附註」。
- 用表單上方的測試按鈕()試跑,確認輸出符合預期。
LLM 任務特有欄位¶
設定分頁¶
| 欄位 | 必填 | 預設 | 說明 |
|---|---|---|---|
| 大型語言模型 | 是 | 無 | 選擇這次呼叫要用的 LLM 資源。選定後可用旁邊的調整()圖示開啟設定對話框,覆寫該資源的系統提示詞與模型參數。對話框的「進階設定」摺疊層可調整溫度、最大 Token 數、Top P、Top K、是否啟用思考功能,以及「延遲效能設定」(指定供應商的延遲/效能取捨選項,影響回應速度與品質的平衡)。覆寫只對這個步驟生效,不影響資源本身。也可切換為從工作流程輸入帶入。 |
| 對話 | 是 | 一列空白的使用者訊息 | 提供給模型的對話內容,是一張可多列的表格。每列包含 角色 與 內容 兩個欄位(見下表)。模型會依這串對話的上下文產生回覆。也可整體切換為用 JSONPath 從輸入帶入。 |
對話表格的每列欄位¶
| 欄位 | 必填 | 預設 | 說明 |
|---|---|---|---|
| 角色 | 是 | 使用者 | 這列訊息的發話方。使用者代表使用者在對話中輸入的內容;系統助理代表大型語言模型先前產生的回覆內容。可選角色會依所選模型支援的種類而定,但一般都支援這兩種。此欄位在「編輯對話」對話框中設定(見下方對話列的「編輯對話」)。 |
| 內容 | 是 | 空白 | 這列訊息的實際內容,是一張可多列的子表(每列有名稱與類型)。設定流程為兩層:先點對話列的編輯鈕開啟「編輯對話」對話框,再點內容子表某列的編輯鈕開出「編輯內容」對話框,在裡面選擇「提示詞來源」、填入文字或樣板,並把前一步的資料帶進來(見下方對話列的「編輯對話」與內容區塊的「編輯內容」)。 |
「系統提示詞」不是對話裡的一個角色
對話表格只有「使用者」與「系統助理」兩種角色,沒有「系統」角色。要給模型固定的角色定位與規則,請寫在系統提示詞——它是獨立欄位,透過「大型語言模型」欄位旁的調整()圖示開啟的設定對話框設定(見上方截圖最上方的「系統提示詞」)。詳細寫法見「怎麼寫提示詞」。
對話列的「編輯對話」¶
點「對話」表格某列的編輯()鈕,會先開啟「編輯對話」對話框。這一層負責設定整列訊息的角色與內容組成:
| 欄位 | 必填 | 預設 | 說明 |
|---|---|---|---|
| 角色 | 是 | 使用者 | 這列訊息的發話方,選「使用者」或「系統助理」。 |
| 內容 | 是 | 一列空白內容 | 一張可多列的子表,欄位為名稱與類型。一列訊息可由多個內容區塊組成(例如一段文字加一張圖片)。點子表某列的編輯()鈕,才會再開出下面說明的「編輯內容」對話框,進一步設定該內容的提示詞來源與實際值。 |
內容區塊的「編輯內容」¶
在「編輯對話」對話框的「內容」子表,點某列的編輯()鈕,會再開出「編輯內容」對話框。除了「名稱」與「類型」(文字/圖片/儲存庫檔案,提示詞請用文字;「儲存庫檔案」可讓這列內容指向你儲存庫資源裡的檔案,而不是直接打字)外,最關鍵的是「提示詞來源」,它決定這列內容怎麼產生:
| 提示詞來源 | 適用情境 | 出現的欄位 |
|---|---|---|
| 自訂提示詞 | 直接寫一段提示詞,不需要樣板變數替換。可在「提示詞」欄右上角勾「JSONPath」開關,整段改用 JSONPath 從狀態帶入單一動態值。 | 提示詞(可勾 JSONPath;附「改寫」工具) |
| 自訂提示詞樣板 | 需要在固定文字裡挖空格、填入多個動態值。用 {{ }} 寫樣板,再用「樣板變數」把值接進來。 | 樣板、樣板變數 |
| 既有提示詞樣板 | 直接套用你事先存好的樣板 (Template) 資源,多個步驟共用同一份樣板時很方便。 | 選擇樣板資源、樣板變數 |
三選一怎麼挑
只塞一段話、最多一個動態值 → 自訂提示詞(需要動態值就勾 JSONPath)。要在一段話裡填多個動態值 → 自訂提示詞樣板。同一份樣板想跨步驟、跨流程重複使用 → 先存成樣板 (Template) 資源,再選 既有提示詞樣板。三者的完整語法與圖解見 Template 語法 與 JSONPath 語法。
進階任務設定(摺疊區塊)¶
展開設定分頁底部的「進階任務設定」,LLM 任務會提供下列特有欄位。共用的「上傳輸出至外部記憶體」「錯誤時中止」等請見 Action 通用設定。
| 欄位 | 必填 | 預設 | 說明 |
|---|---|---|---|
| Guardrail ID | 否 | 空白 | 指定要套用的 Guardrail(內容防護)識別碼,把特定防護設定綁到這次呼叫。 |
| Guardrail 版本 | 否 | DRAFT | 指定要使用的 Guardrail 設定版本,確保套用正確版本的防護規則。欄位預設帶入 DRAFT(草稿版本)。 |
| 備用大型語言模型 | 否 | 無 | 指定一組備援模型。當主模型無法產生回應時,系統會依序改用備援模型,提高成功率。 |
| 允許重試 | 否 | 關閉 | 開關。開啟後,當任務無法產生有效回應時會自動重新產生,且每次重試會把模型溫度加 0.1 以增加變化。這是針對「結果無效」,與錯誤處理分頁針對「呼叫失敗」的重試器不同。 |
執行設定(摺疊區塊)¶
LLM 任務的「執行設定」區塊欄位(上傳輸出至外部記憶體、即時輸出串流、錯誤時中止、預設輸出)皆為共用欄位,說明見 Action 通用設定。
怎麼寫提示詞(重點教學)¶
提示詞 (Prompt) 就是你給模型的「指令+資料」。同一個模型,提示詞寫得好不好,輸出品質天差地遠。這一節教你把它拆成幾個位置來寫,並附上可直接照抄改寫的範例。
先搞懂三個位置:系統提示詞、使用者、系統助理¶
一次 LLM 呼叫會把三種東西送進模型,各有分工,別放錯地方:
| 位置 | 在畫面哪裡 | 放什麼 | 會不會每次變動 |
|---|---|---|---|
| 系統提示詞 | 「大型語言模型」欄位旁調整()圖示開啟的對話框最上方 | 模型的角色、任務、規則、語氣、輸出格式——整段對話最上層、最優先的指示 | 通常固定不變 |
| 使用者(對話列) | 「對話」表格中「角色」選「使用者」的列 | 這一次要模型處理的實際輸入(病人主訴、要摘要的文件、客訴內容…) | 多半每次不同,常用動態值帶入 |
| 系統助理(對話列) | 「對話」表格中「角色」選「系統助理」的列 | 模型先前的回覆;主要用來補對話歷史,或放「範例答案」做示範(見多輪對話) | 視用途 |
一句話記:系統提示詞寫「你是誰、要怎麼做」,使用者訊息寫「這次要你做的這一筆」。
動態值放使用者訊息,不要放系統提示詞
系統提示詞用來寫固定不變的角色與規則。會隨每次執行變動的內容(病人主訴、客訴文字…),請放在「使用者」那一列、用動態方式帶入。
寫好系統提示詞 (System Prompt)¶
一個好用的結構是依序交代這幾件事,每件一兩句即可:
- 角色:你是誰、專長領域。
- 任務:要完成什麼。
- 規則/限制:必須遵守或絕對不能做的事。
- 語氣/對象:對誰說、用什麼口吻。
- 輸出格式:要分點、限字數、用哪種語言等。
以「AI 分診助理」為例:
你是一位「AI 分診助理」,專長是一般內科與家醫科分診。
任務:根據病人主訴,建議最合適的就診科別,並說明理由。
規則:
- 只在你有把握時給出單一科別建議;不確定時請建議「家醫科」並提醒就醫。
- 不提供診斷或處方,只做科別分流。
- 若主訴包含胸痛、呼吸困難、意識不清等危急徵象,請優先提醒立即就醫或撥打 119。
語氣:親切、簡潔,面向一般民眾,避免艱深醫學術語。
輸出格式:
1. 建議科別
2. 一句話理由
同一套寫法可換到別的情境:例如氣象署助理可在「語氣/對象」切換「對民眾」或「對署內同仁」,就能讓同一份資料產出不同口吻的回覆。
系統提示詞不支援動態變數替換
系統提示詞欄位是寫固定指示用的。需要隨執行變動的內容請放使用者訊息。若連角色設定本身都想動態切換(例如依輸入決定「對民眾/對署內」),可把整個「大型語言模型」欄位切換成從工作流程輸入帶入,或改用 Agent 的提示詞設計。
寫好使用者訊息 (User Prompt)¶
使用者訊息放「這一次的輸入」。最常見的寫法是:一句說明 + 帶入動態資料。例如把病人主訴帶進來:
以下是病人的主訴,請依系統提示詞的規則建議就診科別。
主訴:{{ question }}
其他資訊:{{ additional_context }}
要把上面的 {{ question }}、{{ additional_context }} 換成真正的值,就要靠下一節的「提示詞來源」。
做 RAG(先檢索、再回答)時,把檢索到的內容也一起放進使用者訊息,並明確要求模型「只根據提供的內容作答」:
請只根據下列「參考內容」回答問題,找不到答案就說不知道,不要自行臆測。
問題:{{ question }}
參考內容:
{{ context }}
把動態值帶進提示詞:三種「提示詞來源」¶
提示詞裡要填「會變動的值」(病人主訴、檢索內容、前一步輸出…),就在「編輯內容」對話框選對「提示詞來源」:
-
自訂提示詞 + 勾 JSONPath:整段內容就是一個動態值時最省事。例如使用者訊息只想直接帶入病人主訴,就在「提示詞」欄勾「JSONPath」,填
$.question。寫法見 JSONPath 語法。 -
自訂提示詞樣板:一段話裡要填多個動態值時用這個。在「樣板」用
{{ 名稱 }}挖空格,再到「樣板變數」表格用同名變數把值接進來:「樣板」:
請只根據參考內容回答問題。 問題:{{ question }} 參考內容:{{ context }}「樣板變數」(名稱 → 值,值用 JSONPath 從狀態取):
名稱 值 question$.questioncontext$.RetrievalActionResult.documents完整圖解見 Template 語法。
-
既有提示詞樣板:同一份樣板要在多個步驟或多個流程重複使用時,先把它存成樣板 (Template) 資源,再在這裡選用,並一樣用「樣板變數」接值。改一處、全部沿用。
用 {{ }} 變數,記得在「樣板變數」補上同名的一列
{{ question }} 只是挖了一個叫 question 的空格,本身沒有值。要在「樣板變數」加一列 question、值填 $.question,執行時才填得進去。名字打錯或漏掉,該空格就會留白。
用「改寫」讓 AI 幫你優化提示詞¶
不知道怎麼下筆時,可以先寫一句粗略的指示,再用 AI 幫你補成完整提示詞。在「系統提示詞」欄位或「自訂提示詞」的「提示詞」欄,點工具列的「改寫」()鈕,系統會依你選的模型把提示詞改寫得更清楚、更結構化。改寫結果可再自行微調。
用多輪對話給範例(few-shot)¶
想讓模型照你要的格式或風格回答,最有效的方法之一是「給它看範例」。在「對話」表格交錯排幾組「使用者 → 系統助理」,把理想答案直接示範給它:
| 角色 | 內容 |
|---|---|
| 使用者 | 我一直流鼻水、喉嚨痛兩天了。 |
| 系統助理 | 1. 建議科別:家醫科 2. 理由:屬一般上呼吸道症狀,家醫科可初步評估。 |
| 使用者 | {{ question }} |
模型看到前面的示範,就會用同樣的格式回答最後這筆真正的輸入。示範列不需要動態值;只有最後代表本次輸入的那一列才帶入 {{ question }}。
常見錯誤¶
- ❌ 把規則、角色寫進「使用者」訊息——容易被當成這次的輸入。✅ 固定規則寫在系統提示詞。
- ❌ 在系統提示詞裡放
{{ 變數 }}期待它替換——系統提示詞不做變數替換。✅ 動態值放使用者訊息。 - ❌ 想帶入動態值卻忘了勾 JSONPath 或漏填「樣板變數」——模型收到的是
$.question這串字而非真正的值。✅ 照上一節接好值。 - ❌ 一段提示詞塞太多任務(又要分類又要摘要又要翻譯)——輸出容易失焦。✅ 拆成多個步驟,或改用 結構化大型語言模型 一次輸出多個固定欄位。
實際範例¶
範例一:RAG 文件問答¶
系統提示詞(在調整()對話框):
你是一個協助回答文件相關問題的助理。
請只根據使用者提供的參考內容作答,找不到答案就說「資料中查無相關內容」,不要自行臆測。
對話(角色:使用者;提示詞來源:自訂提示詞樣板):
「樣板」:
問題:{{ question }}
參考內容:
{{ context }}
請根據參考內容提供簡潔、附重點的答案。
「樣板變數」:
| 名稱 | 值 |
|---|---|
question | $.query |
context | $.context |
工作流程輸入:
{
"query": "RAG 有什麼好處?",
"context": "RAG 結合檢索與生成,提供準確、有根據的回應,並附上來源出處。"
}
測試執行輸出:
{
"errors": null,
"action_type": "llm_action",
"output": "RAG(檢索增強生成)的主要優勢包含:回應建立在檢索到的文件上、可追溯來源、能取得最新資訊,並能減少模型虛構內容。"
}
產生的文字會放在 output 欄位,可供後續步驟使用。
範例二:同一份資料、切換受眾語氣¶
只要改系統提示詞的「語氣/對象」,同一筆氣象資料就能產出不同口吻:
系統提示詞(對民眾):
你是氣象署的對外小幫手,面向一般民眾。
請用親切、口語、生活化的方式說明天氣,並給穿著或出行建議,避免專業術語。
系統提示詞(對署內同仁):
你是氣象署的內部助理,面向署內同仁。
請用精確、專業的用語摘要天氣資訊,保留必要的數值與專有名詞。
對話(角色:使用者;提示詞來源:自訂提示詞,勾 JSONPath): $.weather_summary
切換系統提示詞即可在「親切版」與「專業版」之間切換,使用者訊息維持不變。
溫度怎麼設
溫度由所選 LLM 資源或調整()圖示中的覆寫值決定:0.0–0.3 適合事實性、一致的回答(問答、資料擷取);0.4–0.7 適合一般內容生成;0.8–1.0 適合創意寫作與發想。
技術識別¶
- action_type:
llm_action
下一步¶
- 還沒看過提示詞語法?先讀 Template 語法 與 JSONPath 語法。
- 用 檢索 (Retrieval) 或 檢索器 (Retriever) 搭配 LLM 組出 RAG 工作流程。
- 需要模型輸出固定 JSON 結構,改用 結構化大型語言模型 (Structured LLM)。
- 共用設定請見 Action 通用設定。